【ゲーム開発のためのC#入門講座・基礎強化編】ふたつのメモリの特性を理解しよう【#4】

おさらい
値型についてさらっとおさらいしておきましょう。
- 型という情報の中にメモリの必要サイズも含まれている
- 事前にサイズがわかっていればメモリを効率よく扱うことができる
- 必要なメモリサイズが明確な型のことを値型という
値型はメモリサイズが明確なので、メモリを効率よく扱えるんでしたね。さらにプログラマーが適切に型を選択することで、より効率よく利用することができるのでした。
データサイズって全部決められるもの?
でも、使う時点ではメモリの最大サイズがわからないものもありますよね。
例えば文字列のように、設定される文字数によってサイズが変動するもの。配列のように、プログラム側の都合でデータサイズが変動するもの。
実際にコンピュータが命令を実行するまでどのぐらいメモリを必要とするのかわからないデータというものもあります。
string text; //string型の変数は、型情報だけではサイズがわからない
text = "hoge"; //格納する文字列が確定して初めてサイズがわかるそれを今までと同じメモリで扱おうとすると、また非効率な運用に逆戻りしてしまいますよね……はてさて、どうしましょう?
そこで出てくるのが第二のメモリ「ヒープメモリ」です。
第二のメモリ「ヒープメモリ」とは?
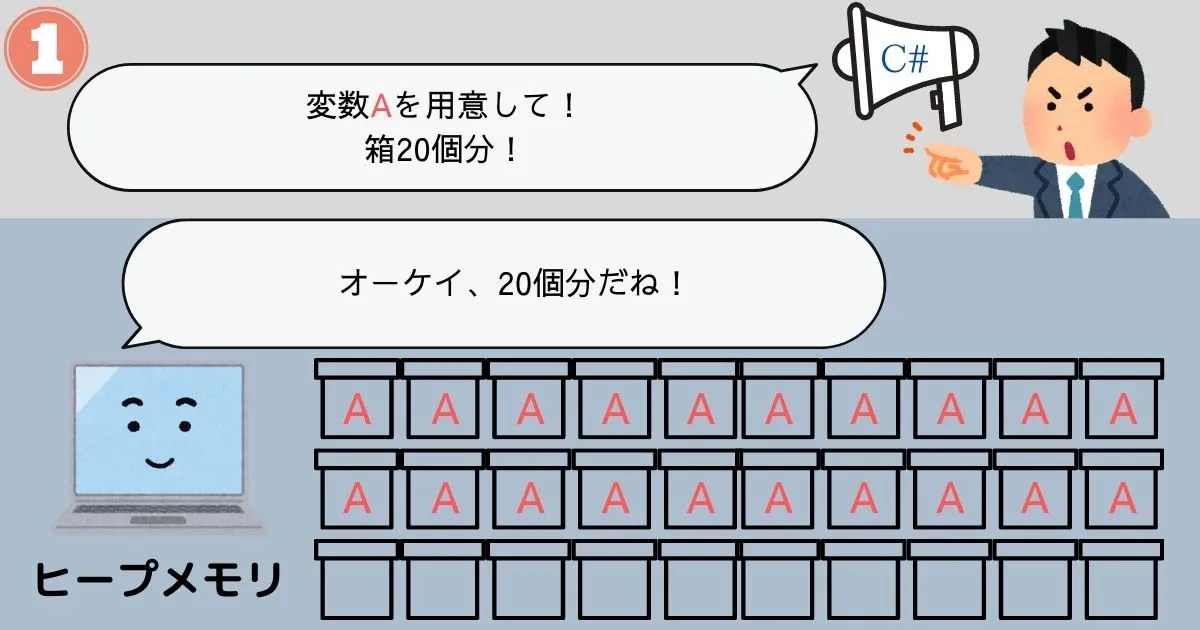
ヒープメモリはサイズがわからないデータ専用のメモリです。
命令を受けてから必要な量だけメモリを確保し、命令を受けてから解放するという運用方法になっています。
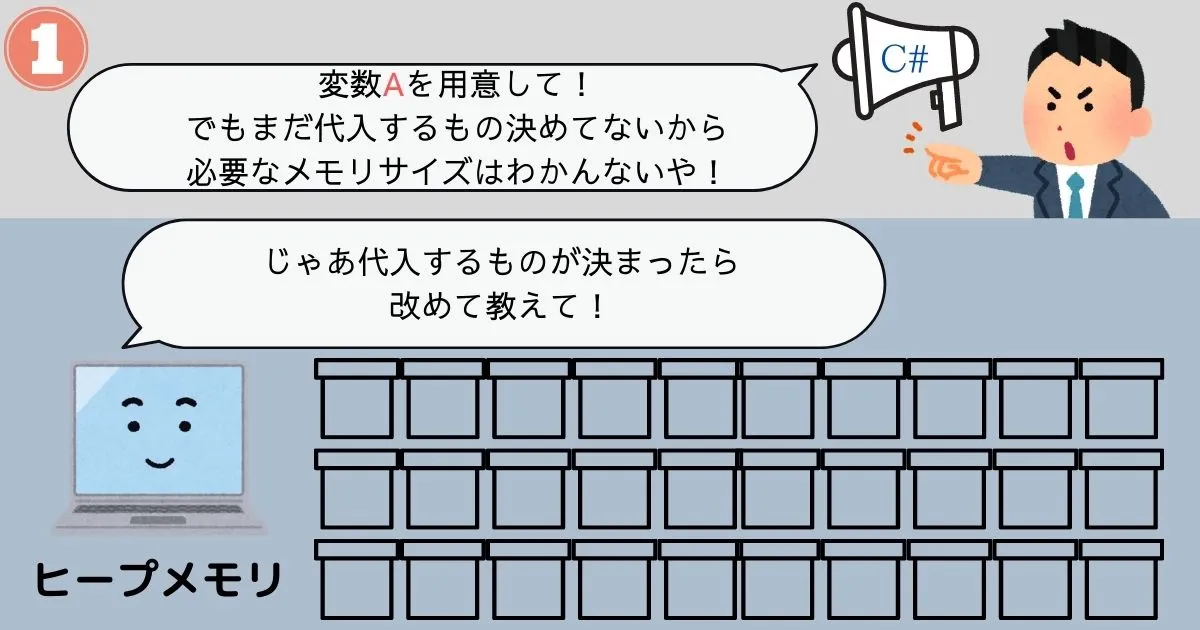
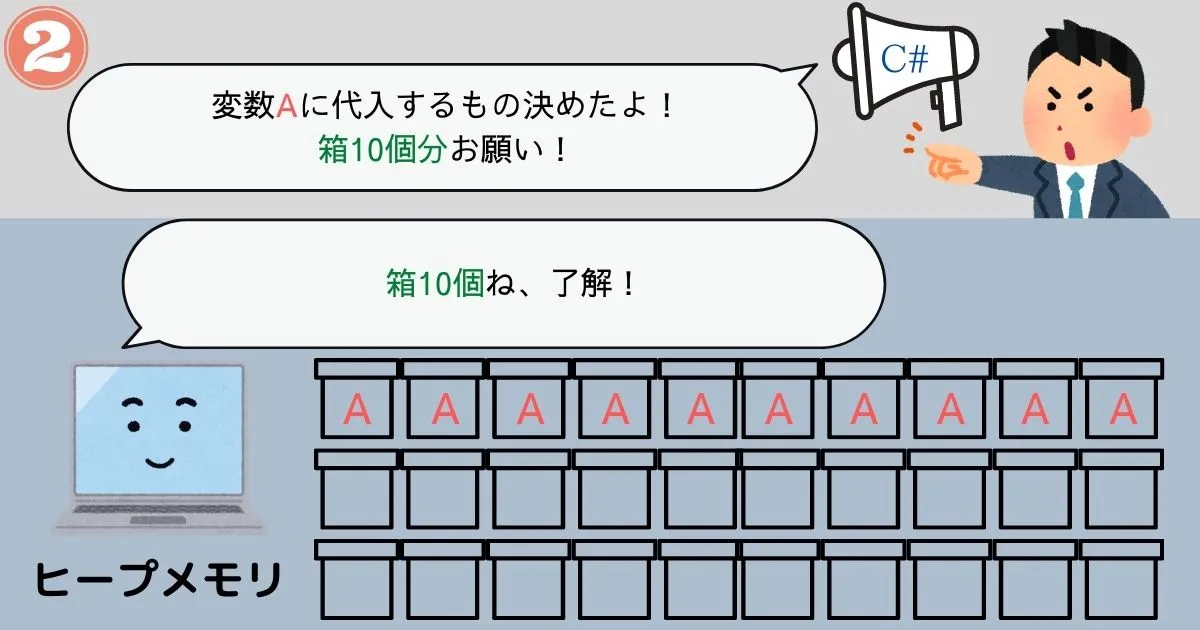
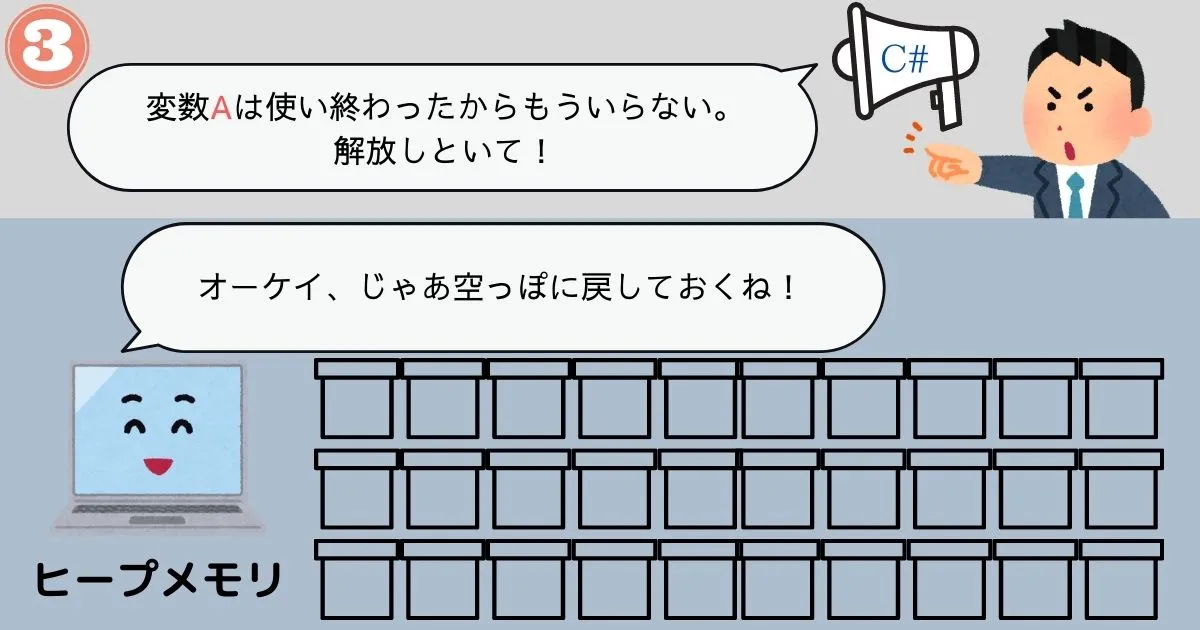
この運用方法なら確かに、命令を実行するまでサイズのわからないデータも管理することができそうです。
え、それができるなら全部そうすればいいじゃんって?
ところがどっこい、この方法にはふたつの大きな弱点があります。
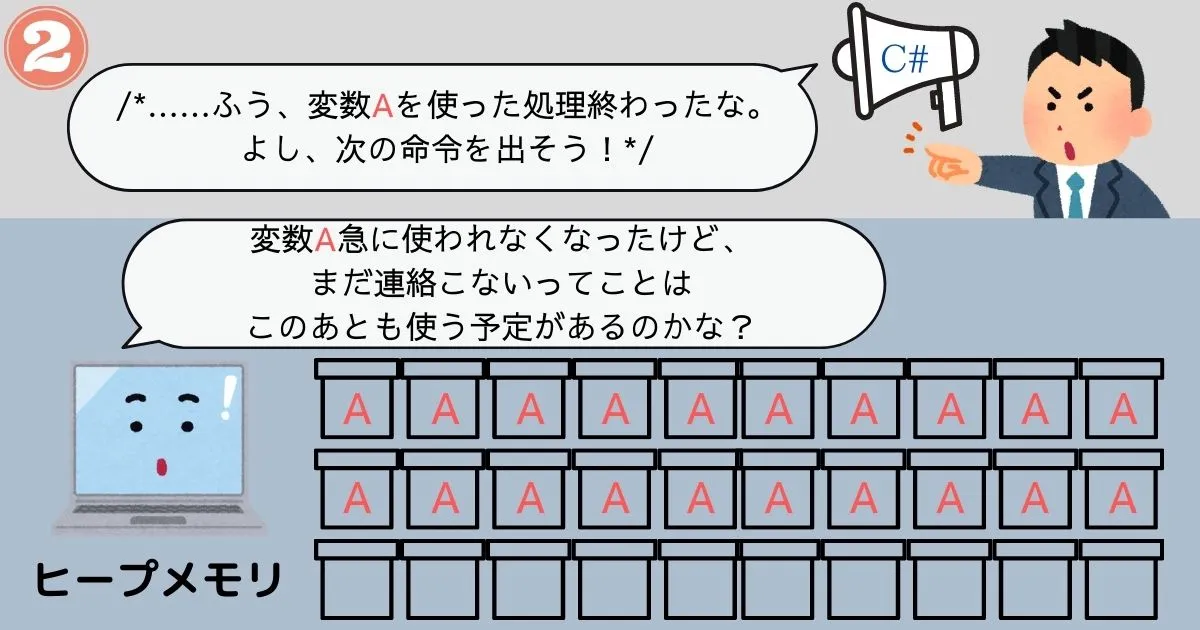
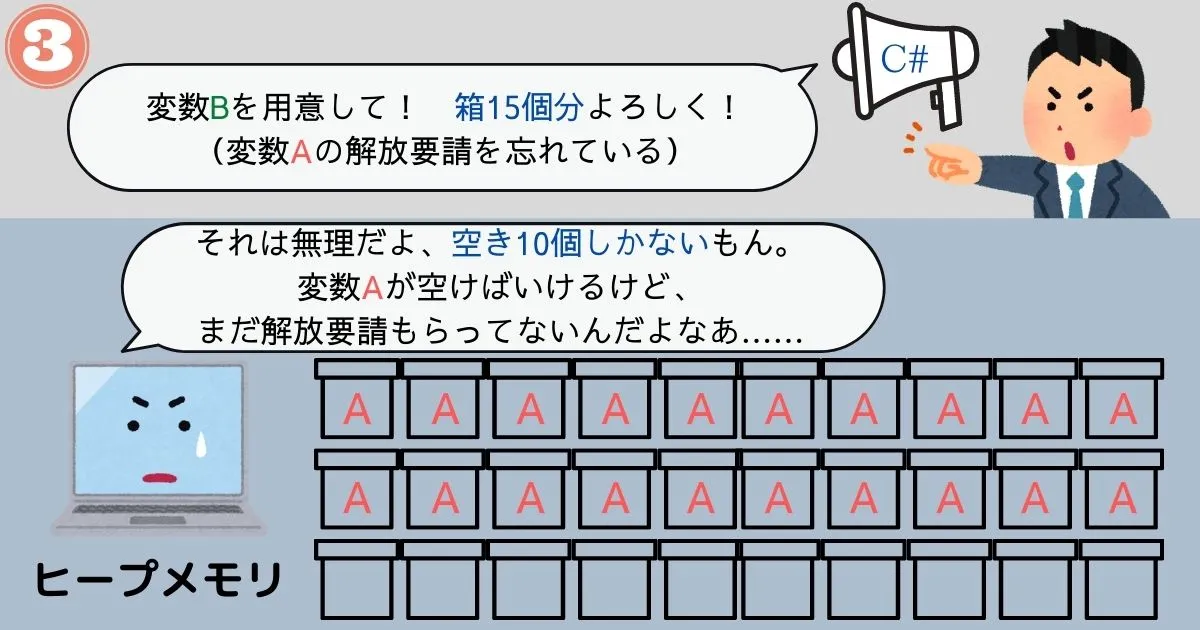
弱点①「フラグメンテーション」
プログラムの都合でメモリを確保したり解放したりすると、徐々にメモリに歯抜けのようなスペースが生まれていくことになります。
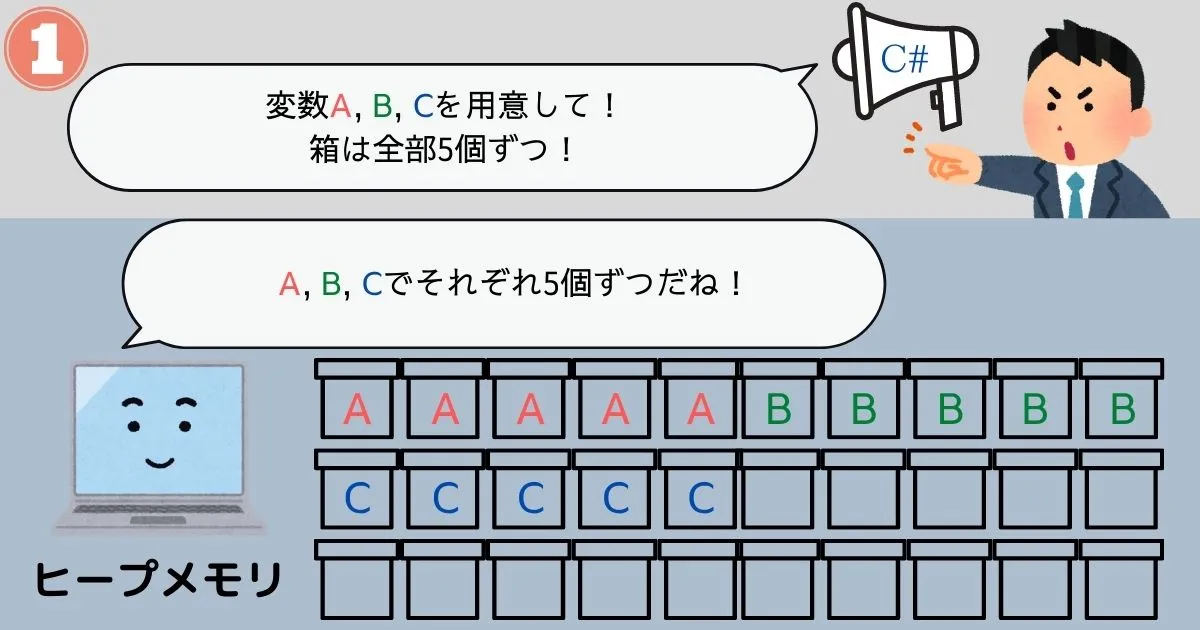

この歯抜けのようなスペースがいくつも発生してしまうことを、メモリのフラグメンテーション(断片化)といいます。
メモリのフラグメンテーションが発生すると、メモリの空き容量的には入るはずのデータが入らなくなる、という問題が発生します。

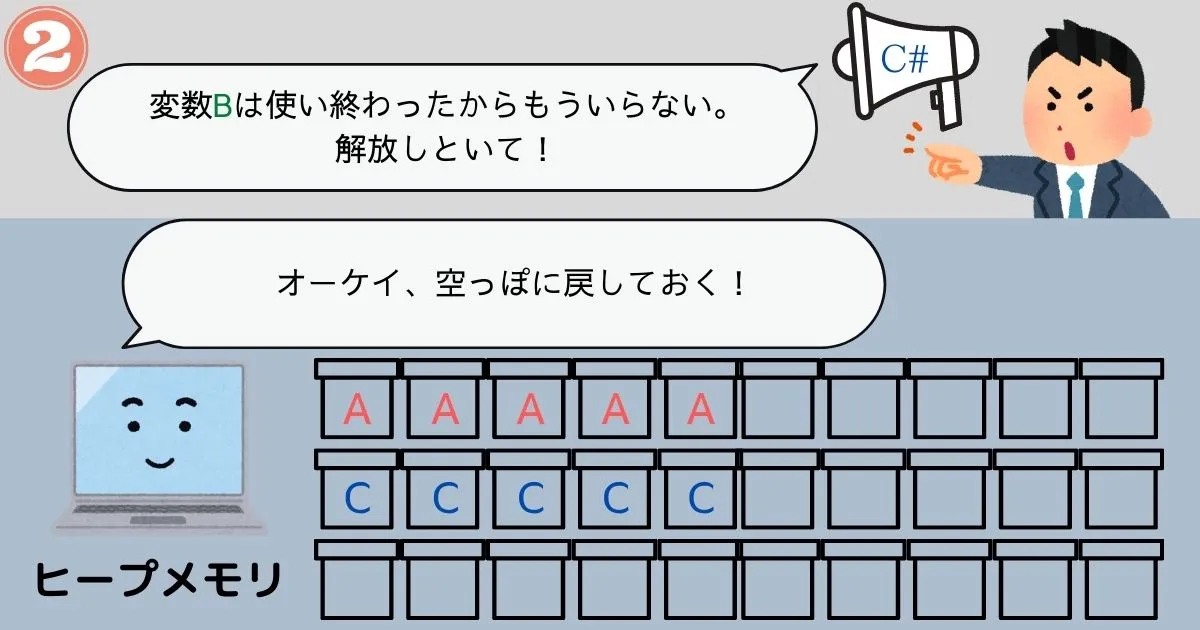
弱点②「メモリリーク」
命令を受けてから必要な量だけメモリを確保し、命令を受けてから解放するということは、プログラムがメモリの解放命令を出すまでメモリ領域が解放されないということ。
つまりプログラマーがうっかり解放命令を記述するのを忘れてしまうと、いつまで経ってもそのメモリ領域を占有してしまうんですね。
これをメモリリークといいます。
メモリリークが続くと、未使用のメモリ領域がどんどん狭まっていくため、メモリがパンクする恐れがあります。
このように、ヒープメモリの運用方法は決して万能ではないんですね。
第一のメモリの運用方法
対して、第一のメモリはサイズが明確なデータだけを関数単位で管理する運用方法となっています。
- 関数の実行開始時に、関数内で使う変数分のメモリをまとめて確保
- 関数内の処理を実行(1.で確保したメモリ領域で変数の読み書き)
- 関数の実行終了時に、1.で確保したメモリ領域をすべて解放
この第一のメモリはスタックメモリと呼ばれています。

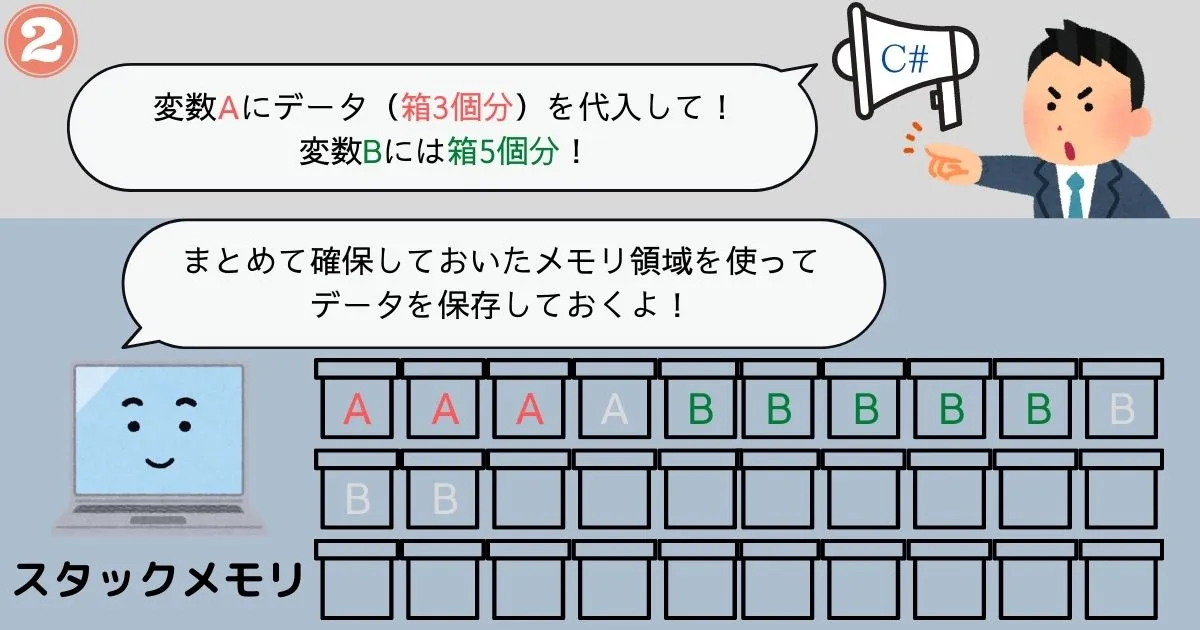
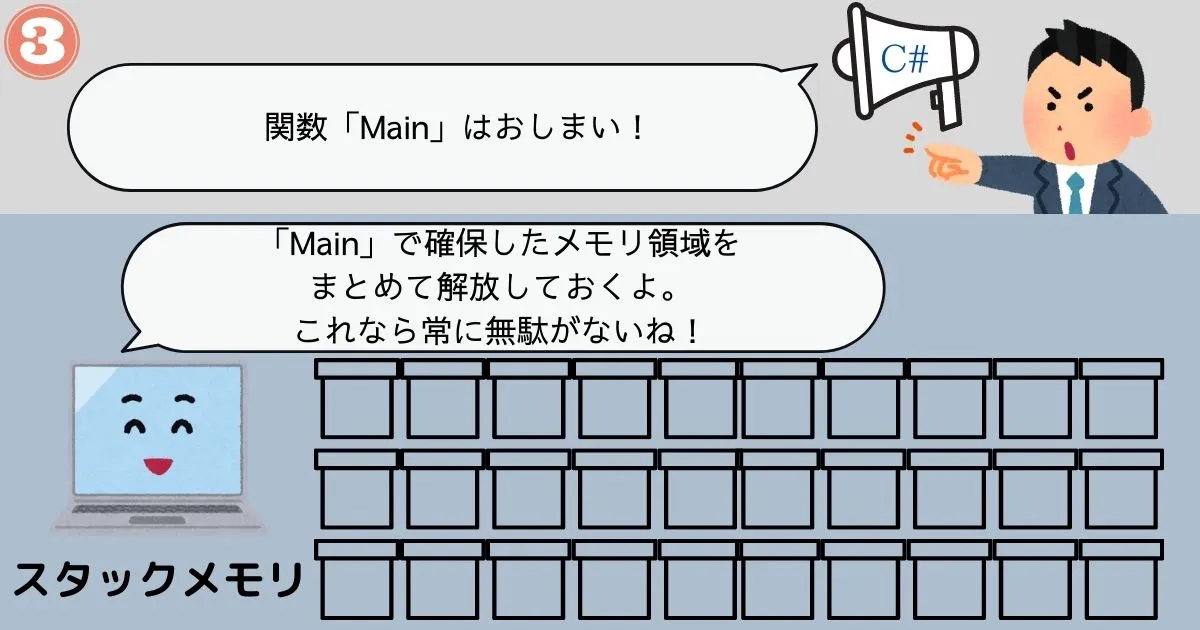
このように確保するタイミングと解放するタイミングが明確なので、プログラム側で制御する必要がありません。 コンピュータが自動的にやってくれることになっています。だからメモリリークが発生することはないんですね。
また、関数単位で必要なメモリ領域を一括で確保・解放するため、部分的にメモリが解放されることがありません。常に隙間なくメモリを運用することができます。だからメモリのフラグメンテーションが発生する恐れもないのです。
つまり、
- 第一のメモリ「スタックメモリ」の運用方法は、メモリリークやフラグメンテーションの恐れがない反面、メモリサイズがわからないデータを扱うことはできない
- 第二のメモリ「ヒープメモリ」の運用方法は、メモリリークやフラグメンテーションのリスクはあるが、メモリサイズがわからないデータを扱うことができる
C#ではこのように、それぞれの欠点を補い合うふたつのメモリを用意して様々なデータを扱えるように工夫しているんですね。
Unityでの活躍ポイント
メモリの話ってなかなか難しいですよね。これ学んでゲーム開発に役立つのかよって思う方もいるかもしれません。が、これは次回学習予定の参照型を理解するために必要な知識なんです。
この参照型には、プログラマーが独自に定義した型がすべて該当します。これまではintやfloatのように最初から用意されていた型を使ってきましたが、今後は自分で独自の型を作っていくことになるんですね。
この独自に定義した型を使うと、今までHPやATKなどのパーツ毎に変数を用意していたところを「勇者」「魔法使い」のようにもっと大きな単位で扱えるようになります。そうするとプログラミングの自由度が一気に広くなります。
便利な参照型ですが、落とし穴が多い機能でもあります。
その落とし穴に落ちないように、あるいは落ちたとしてもすぐに這い上がれるようにしておくために、メモリの話を学んでおく必要があるんですね。
まとめ
第一のメモリ「スタックメモリ」の特性
- サイズが明確なデータだけを関数単位で管理する運用方法
- 関数単位で必要なメモリ領域を一括で確保・解放するため、メモリのフラグメンテーションが発生することはない
- コンピュータが自動的にメモリの確保・解放をしてくれるため、メモリリークが発生することはない
第二のメモリ「ヒープメモリ」の特性
- 命令を受けてから必要な量だけメモリを確保し、命令を受けてから解放するという運用方法
- プログラム側の都合でメモリを管理できる反面、メモリのフラグメンテーションが発生してしまう
- プログラマーがうっかり解放命令を記述するのを忘れてしまうと、メモリリークが発生してしまう
最後に
今回は知識だけなので演習はありません。
次回は第二のメモリ「ヒープメモリ」で扱うデータ種類「参照型」について学習します。
それでは、今回もお疲れ様でした!
また次の記事でお会いしましょう!
お借りした素材一覧
この記事では下記サイト様の素材をお借りしています。
ありがとうございました!